
Les principes de l’architecture RAG expliqués aux professionnels IT
Votre ChatGPT hallucine encore ? Les réponses de vos LLM s’éloignent trop souvent de la réalité ? L’architecture RAG (Retrieval Augmented Generation) résout ce problème majeur des modèles de langage actuels.
Cette innovation combine la puissance générative des LLM avec une base documentaire externe, apportant contexte et précision factuelle aux réponses générées. Fini les informations obsolètes ou inventées ! Les entreprises adoptent désormais cette architecture pour créer des applications d’IA qui accèdent à leurs données spécifiques, sans compromettre la fluidité du langage naturel.
Découvrez dans cet article une introduction aux principes techniques qui font du RAG la solution préférée des professionnels IT.

Qu’est-ce que l’architecture RAG ?
L’architecture RAG (Retrieval Augmented Generation) combine la puissance des grands modèles de langage avec la récupération d’informations externes (la fameuse data). Cette technique augmente les capacités des LLM en leur donnant accès à des documents ou des bases de données spécifiques avant de générer une réponse.
Notebook LM est un exemple emblématique d’outil RAG grand public, car il combine la puissance d’un LLM avec la récupération ciblée d’informations dans une base documentaire privée.
Née en 2020 chez Meta AI Research, l’architecture RAG résout un problème fondamental : les modèles comme GPT stockent leurs connaissances dans leurs paramètres mais ne peuvent accéder à des données récentes ou propres à une entreprise. Le système RAG ajoute une phase de recherche qui extrait les informations pertinentes d’une base documentaire, puis les intègre au prompt du modèle.
Cette approche architecturale a révolutionné les agents conversationnels en associant la fluidité linguistique des LLM à la précision factuelle des moteurs de recherche.
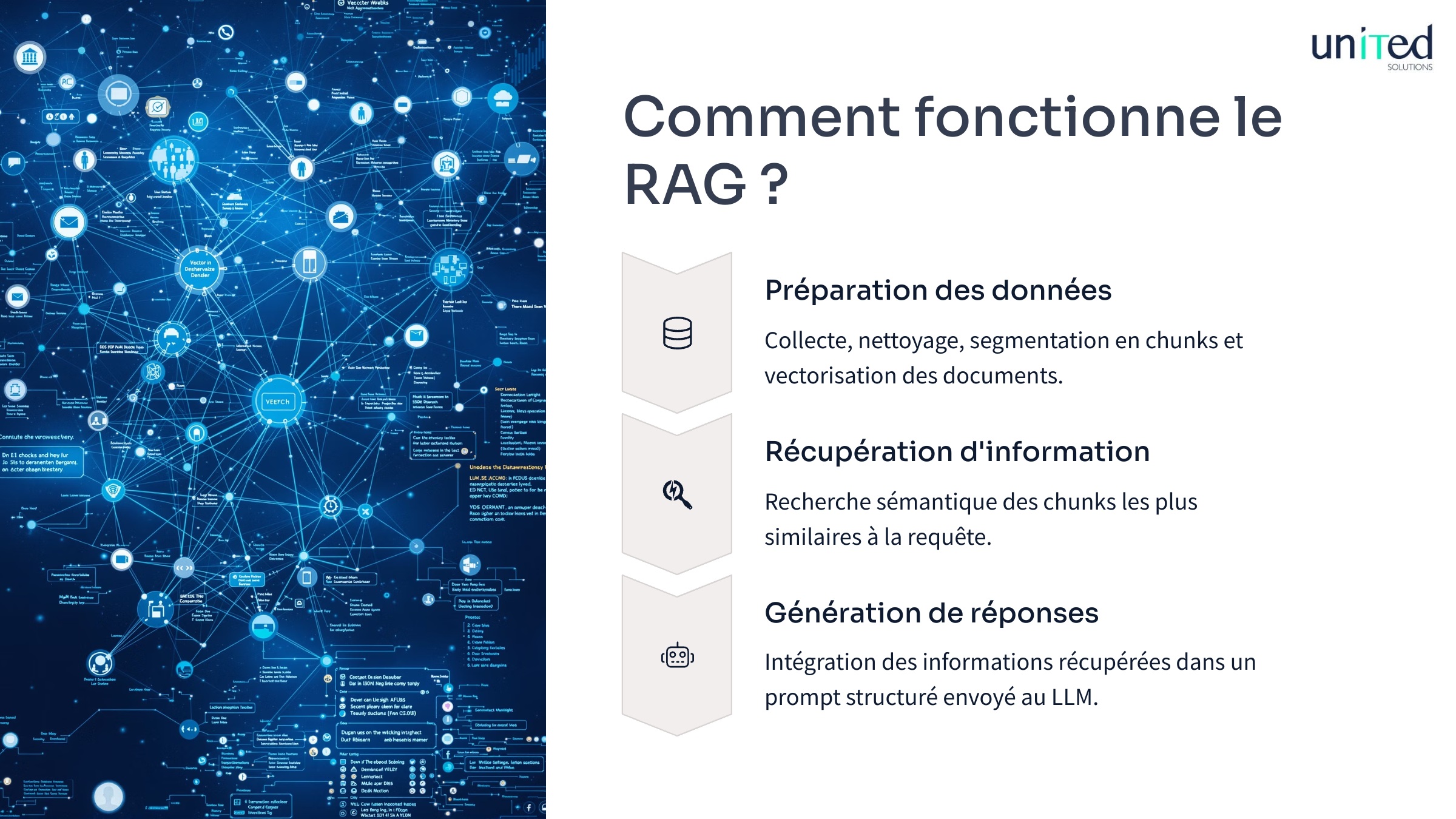
Comment fonctionne le RAG ?
Un système RAG traite les données en trois étapes principales :
- préparation des données,
- récupération d’information
- et génération de réponses.
Cette chaîne de traitement connecte vos bases de connaissances aux capacités des grands modèles de langage via une architecture modulaire.
La préparation des données et les embeddings
La première brique technique d’un système RAG consiste à transformer des documents bruts en vecteurs numériques recherchables. Ce processus démarre par le découpage intelligent des textes en fragments (chunks) manipulables par le système.
Les étapes essentielles de préparation incluent :
- Collecte des sources : extraction de textes depuis des bases documentaires, sites web ou bases de données d’entreprise
- Nettoyage des données : suppression des éléments non pertinents (balises HTML, caractères spéciaux, duplications)
- Segmentation en chunks : découpage en fragments de 200 à 1 000 tokens selon la complexité du contenu
- Vectorisation : conversion de chaque chunk en embedding via des modèles comme BERT ou OpenAI Ada
⚠️ La taille des chunks influence directement la qualité des résultats : des fragments trop petits perdent le contexte global, tandis que des fragments trop grands diluent l’information pertinente.
La phase de récupération (retrieval)
Lorsqu’un utilisateur soumet une requête, le système la convertit en vecteur et recherche les chunks les plus similaires dans la base de données vectorielle. Cette recherche sémantique dépasse la simple correspondance de mots-clés.
L’algorithme calcule la distance (similarité cosinus généralement) entre le vecteur de la question et chaque vecteur stocké. Les documents avec les scores les plus élevés sont considérés comme les plus pertinents. Des solutions comme Pinecone, Weaviate ou Qdrant optimisent ces calculs à grande échelle.
Les techniques avancées incluent la recherche hybride (combinant recherche vectorielle et lexicale) et le re-ranking qui affine les résultats initiaux via un second filtrage plus précis.
La génération augmentée de réponses
La phase finale intègre les informations récupérées dans un prompt structuré envoyé au LLM. Ce prompt contient généralement :
- Les instructions de tâche
- Les fragments de texte pertinents
- La question originale de l’utilisateur
Le modèle génère alors une réponse qui synthétise l’information fournie tout en maintenant un style naturel.
Des techniques comme le « few-shot learning » avec des exemples de réponses idéales améliorent la cohérence et la pertinence des réponses produites.
Quels sont les avantages du RAG pour les entreprises ?
L’architecture RAG apporte aux équipes IT une solution pragmatique face aux limites des grands modèles de langage traditionnels. Cette méthode modifie profondément l’interaction entre les systèmes d’intelligence artificielle et les bases de connaissances des entreprises, avec des avantages mesurables en termes de précision et d’efficacité opérationnelle.
| Bénéfice | Description | Impact business |
|---|---|---|
| Réduction des hallucinations | Les réponses générées s’appuient sur des données externes vérifiables plutôt que sur la seule mémoire du modèle | Fiabilité accrue des assistants conversationnels en contexte professionnel |
| Accès aux données privées | Intégration des sources documentaires internes (documentation technique, wikis, bases de connaissances) | Valorisation du capital informationnel de l’entreprise sans exposition externe |
| Mise à jour en temps réel | Actualisation des connaissances sans réentraînement coûteux du modèle de langue | Réduction des coûts de maintenance et adaptation rapide aux nouvelles informations |
| Contrôle des sources | Traçabilité complète des informations utilisées pour générer les réponses | Transparence et conformité avec les exigences réglementaires |
| Optimisation des ressources | Utilisation de modèles plus légers compensée par la récupération intelligente de contexte | Diminution des ressources computationnelles requises par rapport au fine-tuning |
Comment construire un RAG ?
Mettre en place un système RAG demande une approche structurée et des choix techniques judicieux à chaque étape. Voici un guide pratique pour construire votre pipeline RAG, de la conception à la mise en œuvre opérationnelle.
- Définition des objectifs et préparation
- Identifiez le domaine d’application et les sources de données à intégrer
- Sélectionnez un modèle de langage adapté à votre budget et vos besoins (OpenAI, Google Cloud Vertex AI, Hugging Face)
- Évaluez le volume de données à traiter pour dimensionner l’infrastructure
- Ingestion et préparation des données
- Extrayez le contenu depuis vos sources (API, bases documentaires, web)
- Normalisez les formats (texte brut depuis PDF, HTML, etc.)
- Décidez d’une stratégie de découpage (par paragraphe, nombre de caractères, ou sémantique)
- Choisissez un modèle d’embedding (Ada, BERT, Sentence-Transformers)
- Configuration de la base vectorielle
- Sélectionnez une solution de stockage vectoriel (Pinecone, Weaviate, Chroma, Qdrant)
- Indexez vos vecteurs avec la distance adaptée (cosinus généralement)
- Définissez une stratégie de mise à jour des données (batch ou temps réel)
- Développement du module de récupération
- Créez les fonctions de transformation de requête
- Implémentez la logique de recherche et filtrage
- Configurez le nombre optimal de documents à récupérer par requête
- Intégration avec le générateur LLM
- Concevez vos templates de prompts
- Établissez la communication avec l’API du modèle
- Paramétrez la génération (température, longueur, etc.)
Ces briques s’assemblent dans un pipeline complet qui traite les questions utilisateurs et produit des réponses contextualisées à partir de vos données spécifiques.
Quels sont les cas d’utilisation du RAG ?
L’architecture RAG trouve sa place dans un large éventail de secteurs où l’accès précis à l’information crée une valeur ajoutée significative. Cette technologie s’adapte à de nombreux scénarios business où les grands modèles de langage doivent manipuler des données spécifiques, confidentielles ou fréquemment mises à jour.
| Secteur | Application | Bénéfices |
|---|---|---|
| Santé | Chatbot d’assistance médicale avec accès à la documentation scientifique récente | Réponses précises sur les protocoles de soins sans hallucinations dangereuses |
| Finance | Analyse de rapports financiers et assistance réglementaire | Extraction d’insights précis à partir de grands volumes de données structurées et non structurées |
| Service client | Agents conversationnels avec accès à la base de connaissances produit | Réduction du coût de formation et résolution plus rapide des questions techniques |
| Juridique | Recherche et synthèse de jurisprudence | Analyse de textes légaux complexes avec génération de résumés pertinents |
| Éducation | Tuteurs personnalisés adaptés aux ressources pédagogiques spécifiques | Apprentissage personnalisé basé sur le matériel de cours existant |
| Développement logiciel | Assistant de documentation technique | Aide à la compréhension et l’utilisation d’API ou frameworks open source |
Ces implémentations démontrent la polyvalence du modèle RAG qui excelle particulièrement dans les environnements où la précision des réponses et l’intégration de sources spécifiques prévalent sur la génération créative pure.
United Solutions peut vous aider à déployer une architecture RAG
L’architecture RAG change la manière dont vos applications d’IA interagissent avec vos données d’entreprise. Cette technologie générative établit un pont entre vos datasets existants et les capacités avancées des grands modèles de langage.
United Solutions dispose des compétences techniques pour créer votre pipeline RAG complet, du prétraitement des données à l’optimisation des composants de recherche vectorielle. Notre équipe maîtrise les mécanismes de réglage fin qui amélioreront vos chatbots et applications d’IA.
Contactez-nous pour obtenir un accompagnement adapté à votre contexte et vos objectifs business.
Accédez au potentiel de l’IA générative !

Christophe se forge depuis plus de 12 ans une solide expertise dans le domaine de la transformation digitale et de ses enjeux auprès des clients, notamment en tant que responsable de centre de profits en ESN.